Strings in Rust: how they differ from C
If you come from C, Rust strings will probably feel unfamiliar at first. The underlying concepts are the same: bytes in memory, pointers, lengths. What's different is that Rust wasn't built under the same constraints, so it made different tradeoffs. Let's start from the ground up.
Strings in C
In C, a string is a char*. A pointer to a sequence of characters that ends when you hit a null byte. That's the entire contract.
char *s = "hello";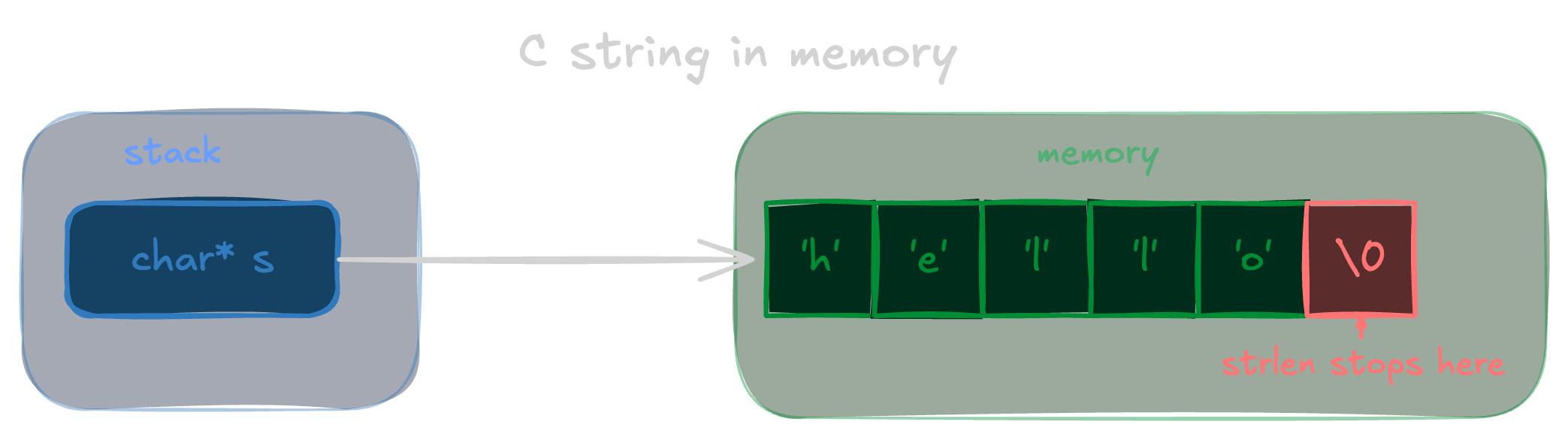
There's no length stored anywhere. If you want to know how long the string is, you call strlen, which walks every byte until it finds \0. That's O(n). Every time.
size_t strlen(const char *s) {
size_t len = 0;
while (s[len] != '\0') {
len++;
}
return len;
}This also means you can't have a null byte in the middle of a string in any meaningful way. The moment strlen or any standard function hits \0, the string is over as far as they're concerned.
It works, and it's simple, but you're trading a lot for that simplicity. C was designed in the early 70s under real constraints: memory was scarce, hardware was limited, and storing an extra integer alongside every string was not a free decision. And it wouldn't even be a single byte: 1 byte caps you at 255 characters, so you'd need at least 2 or 4 bytes to store anything useful, which starts to feel expensive on machines with kilobytes of RAM. The null terminator was a pragmatic call for its time.
But it also means every time you allocate or copy a string, you have to remember to account for it. That extra + 1 for the null byte is easy to forget:
char *s = "hello";
char *copy = malloc(strlen(s)); // wrong, should be strlen(s) + 1
strcpy(copy, s); // writes '\0' past the allocationThis class of bug has caused more security vulnerabilities than most people care to count. The null terminator is not just a performance tradeoff, it's an ongoing source of correctness problems that you carry with you every time you touch a string.
Understanding memory first
To understand why Rust does it differently, the easiest way is to understand memory itself, without a bunch of abstractions.
When a program runs, the OS loads it into RAM and gives it a structured chunk of memory to work with. There's a lot going on in there, but we only need to care about three regions today.
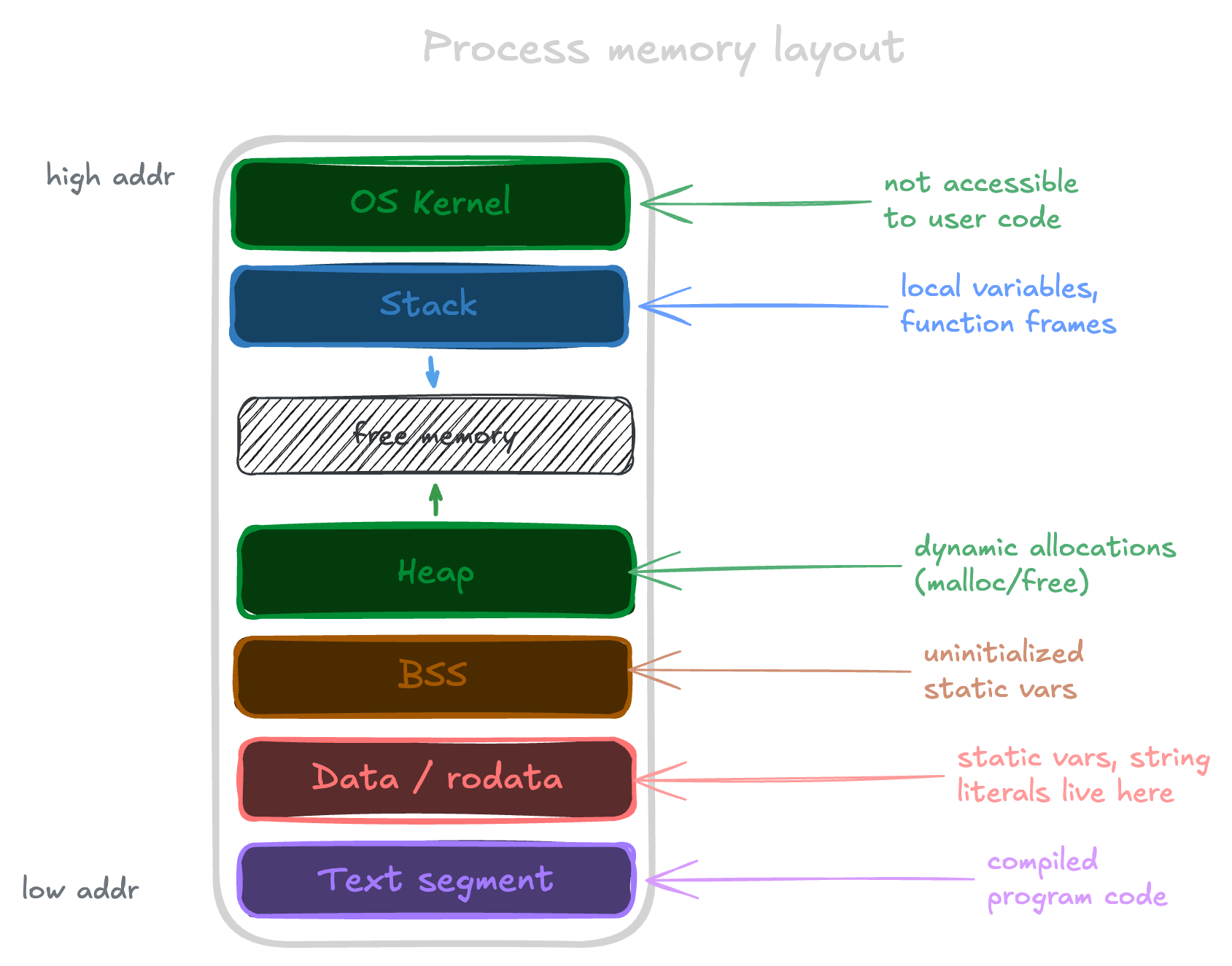
The stack is where local variables live. Every time you call a function, a new frame is pushed onto the stack with space for that function's variables. The size of everything on the stack must be known at compile time, because the compiler has to calculate how much space each frame needs before the program runs. When the function returns, the frame is popped and that memory is gone.
The heap is a pool of memory you can request chunks from at runtime, in sizes you don't need to know ahead of time. The allocation lives until you explicitly free it, or in Rust's case, until the owner goes out of scope.
The rodata segment is where read-only data lives, things baked into the binary at compile time that never change.
With that in mind, strings start to make a lot more sense.
Rust takes a different bet
What if you just stored the length? Then you wouldn't need a sentinel value at the end. You wouldn't need to walk the bytes to find the size. A null byte would just be a byte. No more + 1, no more walking until you find something that isn't the string.
That's what Rust does. The tradeoff is a few extra bytes per string. The gain is that an entire class of bugs simply stops existing. You can't forget to account for a null terminator that isn't there. You can't read past the end of a string because the length is always known. The size is part of the type, not a convention you have to remember to follow.
But where exactly that length lives depends on where the string lives. There are three cases worth understanding.
Stack strings
let s: [u8; 5] = *b"hello";
The bytes live directly in the stack frame. There is still a pointer involved when you take a reference to it, but that pointer points back into the stack itself, not somewhere else. Nothing is allocated on the heap, nothing is looked up elsewhere.
The limitation is the same as anything else on the stack: the size must be known at compile time. [u8; 5] and [u8; 10] are completely different types. It is closer to char s[5] in C than to anything you would normally call a string, but the memory layout is the same idea.
The immutable ones
The most common compile-time case is the string literal. Its bytes are placed in the rodata segment before your main even runs, and they stay there for the entire lifetime of the program. You can't modify them and you don't need to free them.
let s = "hello";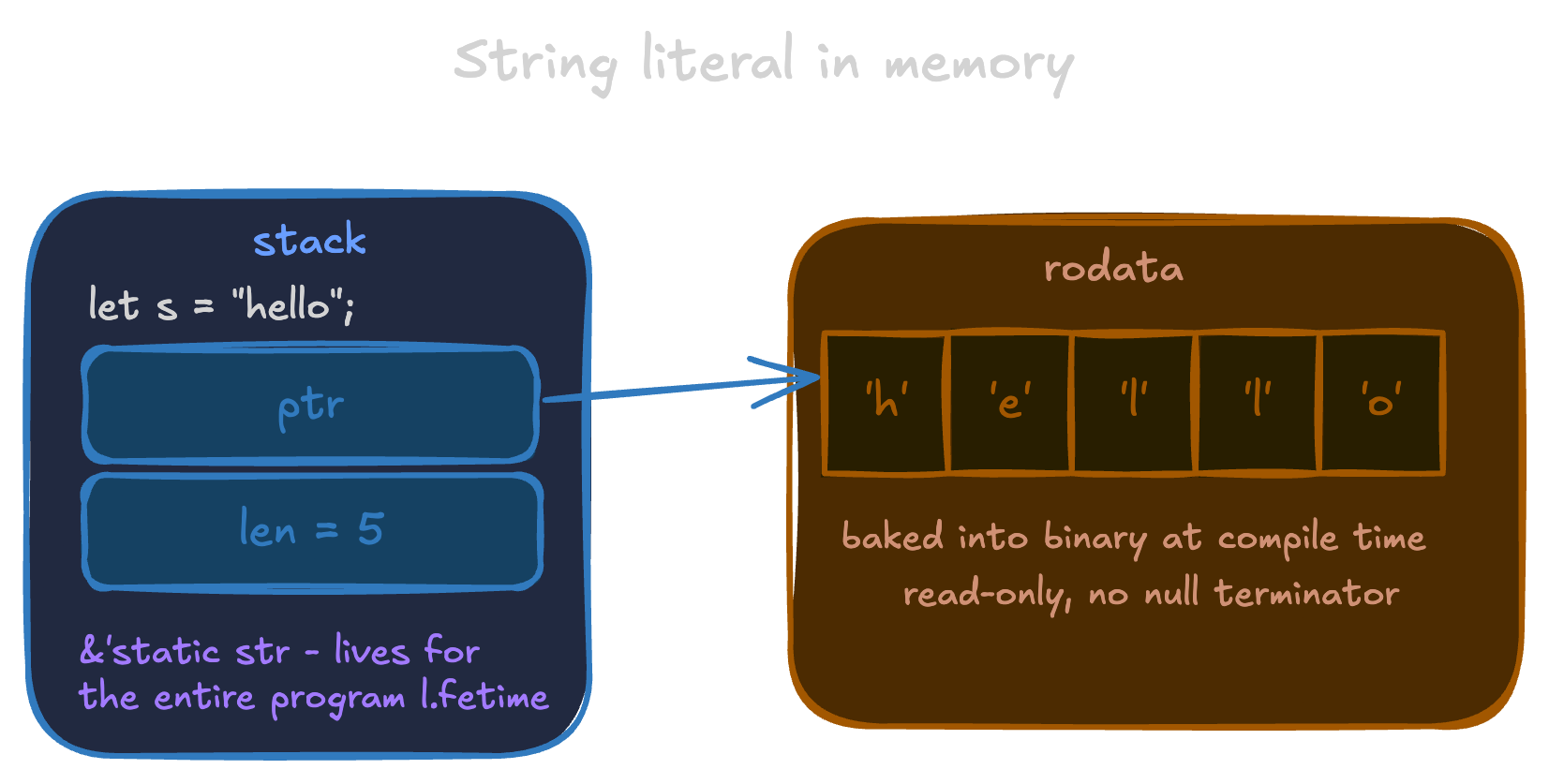
No heap, no capacity. Just two fields on the stack: a pointer to the bytes and their length. This is what is generally called a fat pointer, a pointer that carries extra metadata alongside the address. A regular pointer is just an address. A fat pointer is an address plus something else, in this case the length. The type is &'static str. Static because the data lives for the entire duration of the program.
The heap case
The heap case is what you get when the string needs to be dynamic: it can grow, shrink, be built at runtime from user input or a file or a network response. You don't know the content at compile time, so the bytes can't live on the stack or in rodata. They go on the heap.
When you write String::from("hello"), Rust puts the bytes on the heap and creates a struct on the stack to manage them. In Rust, the ownership system handles freeing for you: when the String goes out of scope, the heap allocation is freed automatically.
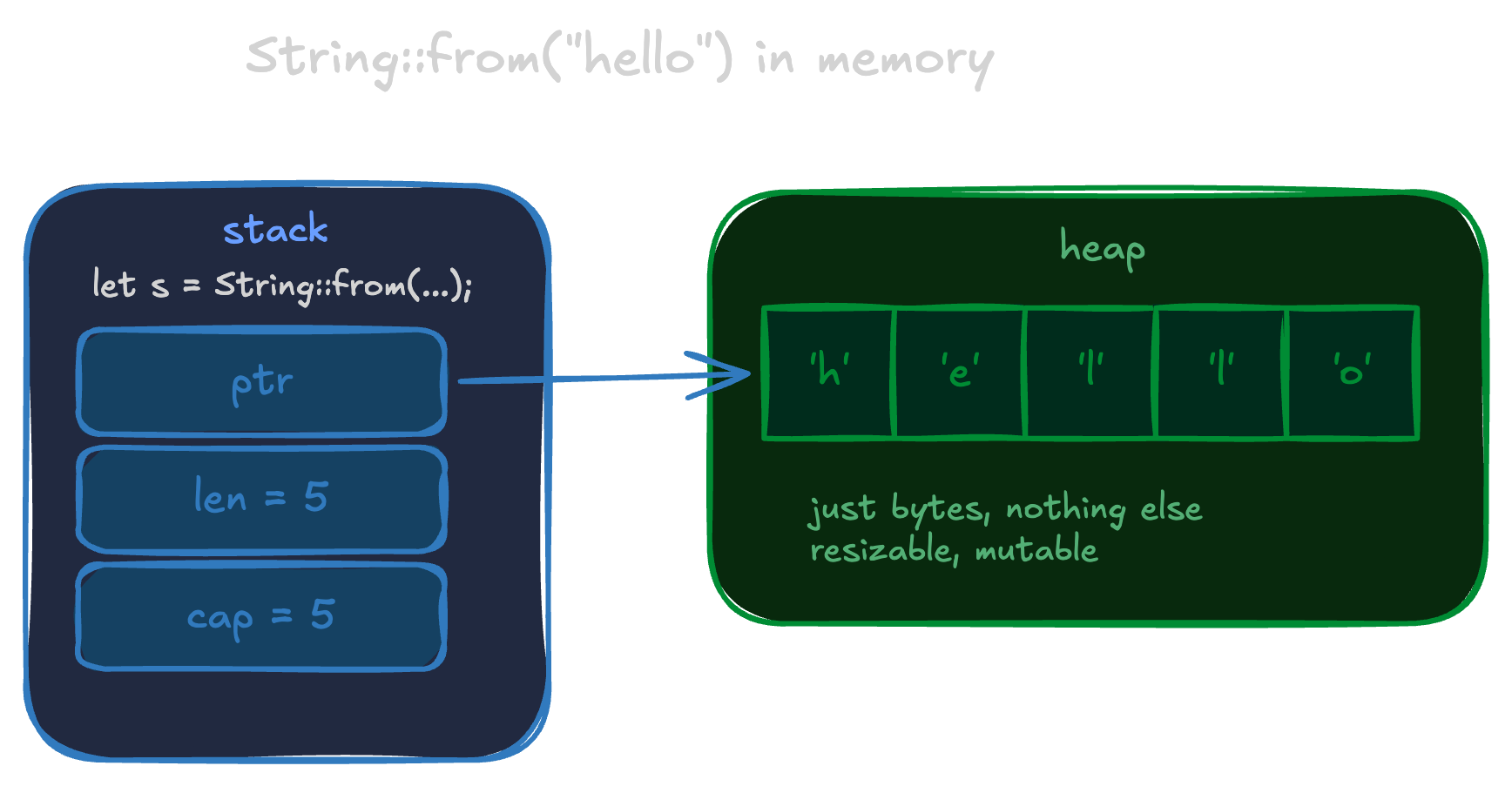
Three fields on the stack: a pointer to the heap allocation, the current length in bytes, and the total capacity. The heap side is just raw bytes. No null terminator. No length prefix sitting next to the data. Nothing but the characters themselves.
The length is not near the data. It lives in the struct, on the stack, separated from what it describes. This matters and will come back later.
You can verify there's nothing after the bytes:
let s = String::from("hello");
let ptr = s.as_ptr();
unsafe {
for i in 0..5 {
print!("{} ", *ptr.add(i)); // 104 101 108 108 111
}
println!("{}", *ptr.add(5)); // whatever was in memory before, not a null byte
}len() in Rust is O(1). You read the field. Done. And a \0 in the middle of a String is just another byte:
let s = String::from("hel\0lo");
println!("{}", s.len()); // 6, not 3str is unsized and that's the problem
You'll see String and &str all over Rust code. But they are not the same thing, and the reason why gets at something fundamental.
str is the type that represents a sequence of UTF-8 bytes. Not &str. Not String. Just str. And you almost never use it directly, because you can't.
let s: str = "hello"; // doesn't compileThe compiler refuses because str is a dynamically sized type, a DST. Its size is not known at compile time. Every value you put on the stack needs a known size so the compiler can figure out how much space to reserve. str has no fixed size. It could be 3 bytes, it could be 300. The compiler cannot reserve stack space for something whose size only exists at runtime.
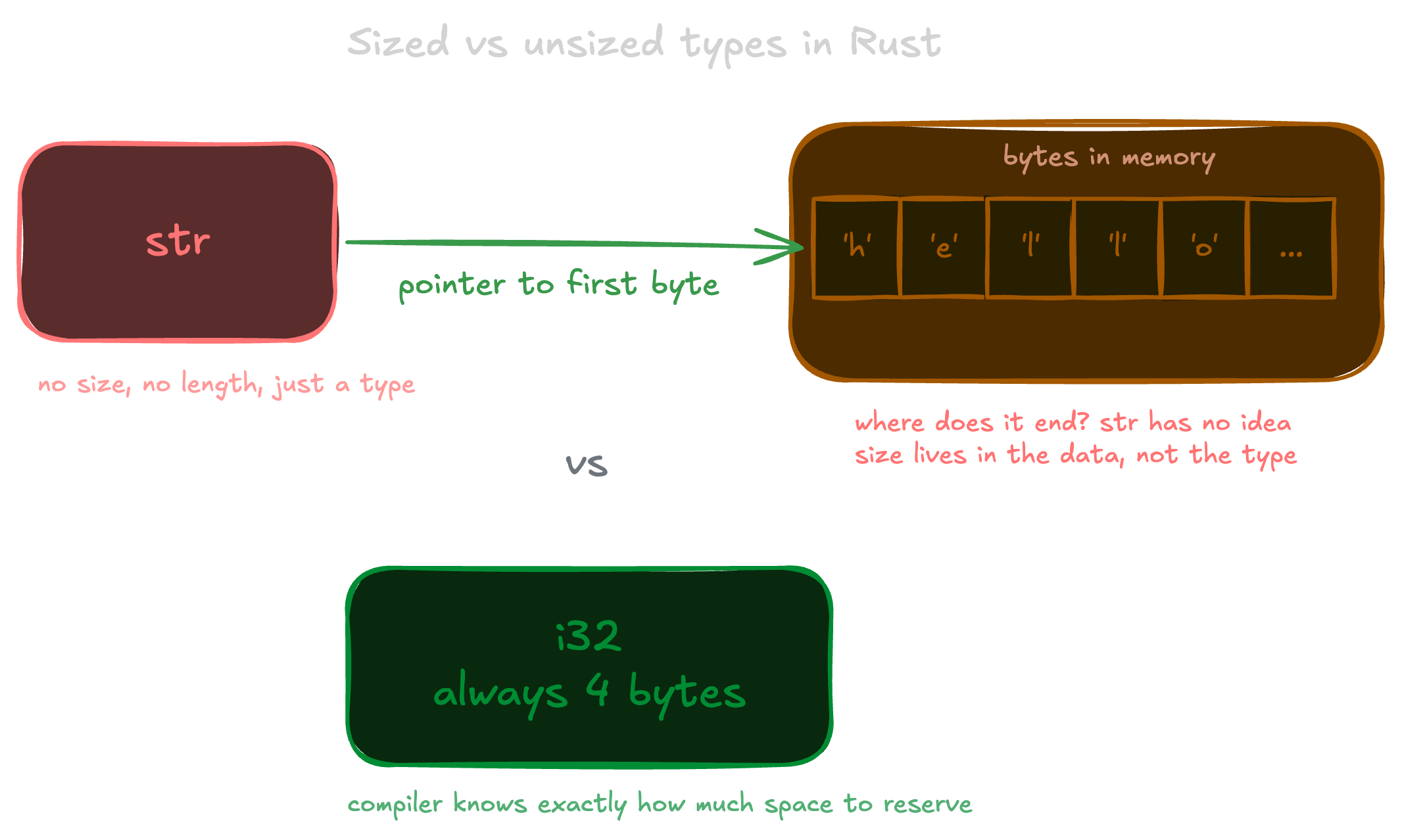
Think about what a slice actually is. [u8] is not a container, it's not a struct, it has no metadata attached to it. It is literally just the bytes themselves, sitting somewhere in memory. A pointer to a [u8] is a pointer to the first byte and nothing else. There is no way to know where it ends without extra information. The size is not in the type, it's in the data, and the data is only knowable at runtime.
str is exactly that: a slice of bytes. Same problem. This isn't specific to strings either. Every slice type in Rust has it. [T] is a DST for the exact same reason, and you can't have a bare [i32] on the stack either.
So you can't have a bare str. You always need to go through a reference, and that reference needs to carry the length with it. Which brings us back to the fat pointer.
&str has to be fat
A normal pointer would not be enough. If &str were just a pointer to the bytes, you'd lose the length, and you'd be back to C territory, walking until you hit a sentinel.
So &str is a fat pointer. Two fields: a pointer to the bytes and the length. The size of &str itself is fixed: two machine words. The size of the str it points to is carried inside it. That's how you hold a reference to an unsized type without losing information. Now the compiler is happy. You can pass &str around, put it on the stack, store it in structs.
You have a String and want a &str
So you have a String. A struct on the stack with ptr, len, and cap, pointing at bytes on the heap. You want a &str: a fat pointer directly to those bytes.
These are different things. How do you get from one to the other?
Manually you'd do this:
let s = String::from("hello");
let ptr = s.as_ptr();
let len = s.len();
// now you have what a &str needsYou pull the pointer and the length out of the struct and construct the fat pointer yourself. Capacity is irrelevant, you leave it behind.
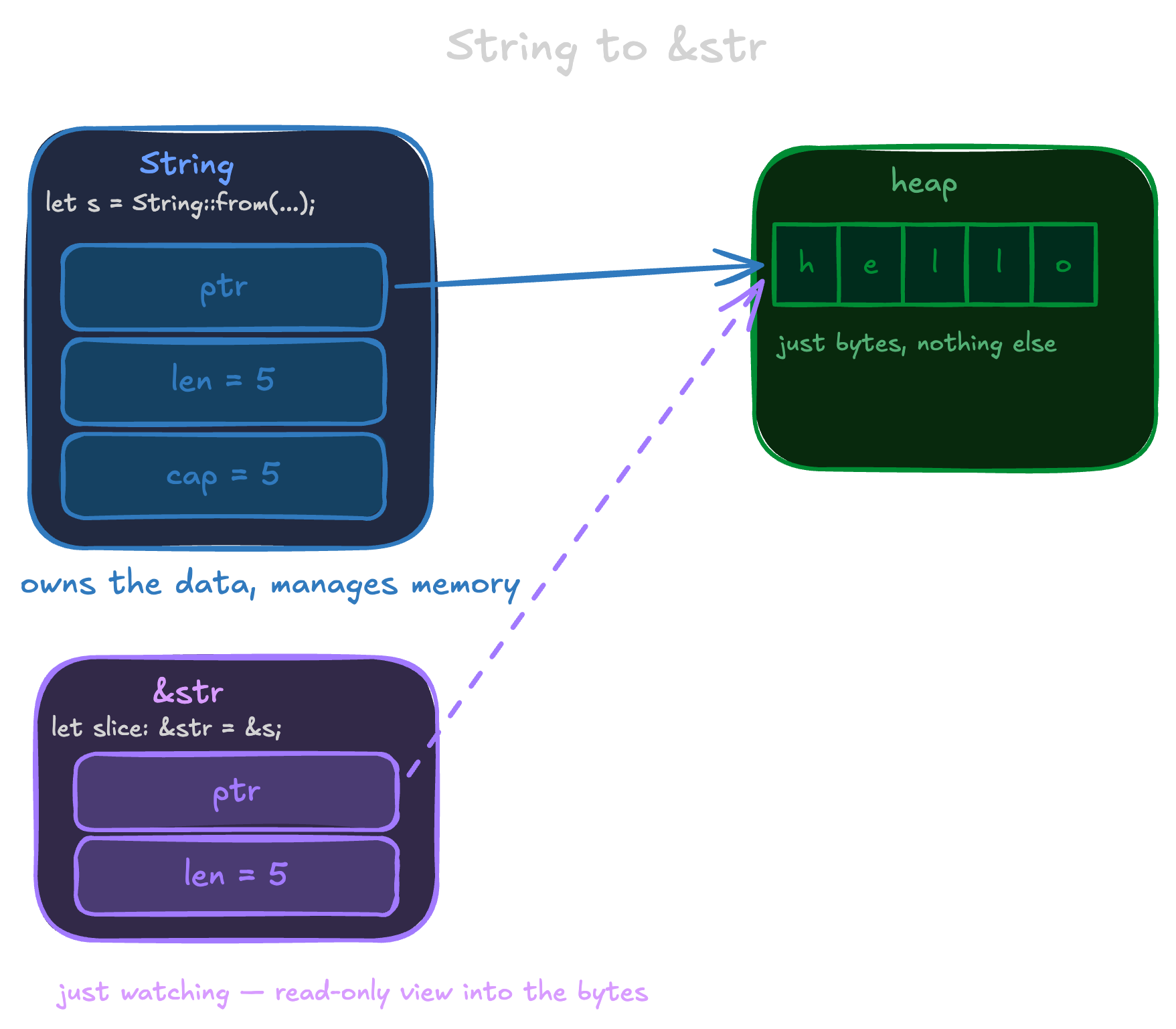
This is exactly what happens when you write:
let s = String::from("hello");
let slice: &str = &s;But it doesn't happen by accident. Something has to automate that extraction. That something is Deref.
Deref is the one to blame
String implements Deref with Target = str. That impl is what makes &String coerce into &str transparently.
Here's a simplified version of what it looks like:
use std::ops::Deref;
struct MyString {
ptr: *const u8,
len: usize,
cap: usize,
}
impl Deref for MyString {
type Target = str;
fn deref(&self) -> &str {
unsafe {
let slice = std::slice::from_raw_parts(self.ptr, self.len);
std::str::from_utf8_unchecked(slice)
}
}
}Look at what deref uses: self.ptr and self.len. That's it. self.cap is never touched. The struct on the stack is the entry point, but what comes out the other side is a fat pointer aimed directly at the heap bytes, with the struct left behind.
This is why &str feels like it skips the struct. It does. Deref extracts exactly the two pieces a &str needs and constructs one, discarding the rest. Coming from C this feels like the compiler is doing something behind your back. But it's not hidden, it's just automated. The real String impl does the same thing, just with safe wrappers around the raw pointer construction.
The FFI boundary
Everything above works because Rust controls both sides. The length is always there, the null terminator is never needed.
But C doesn't know any of this. When you need to pass a string to a C function, you need to go back to the old contract: a pointer to bytes ending in \0.
That's what CString is for:
use std::ffi::CString;
let s = CString::new("hello").unwrap();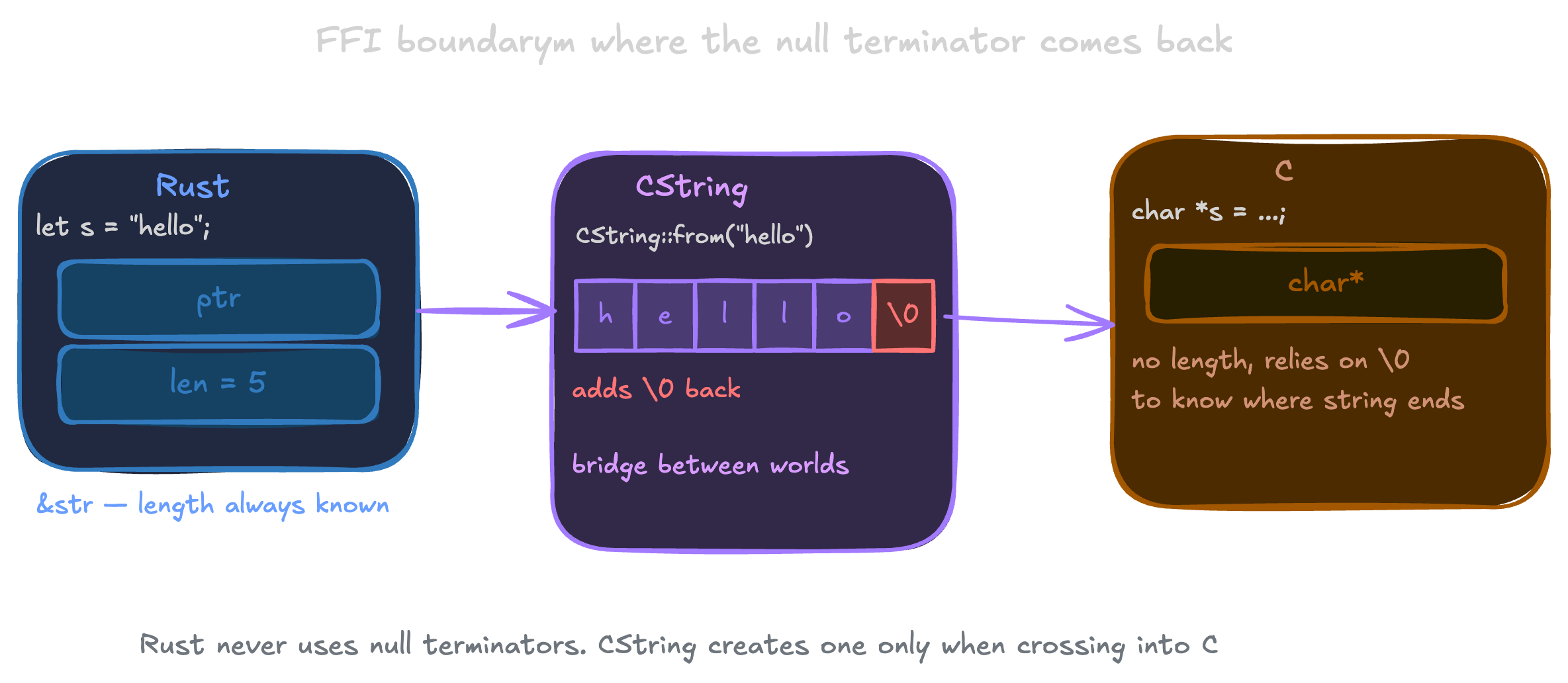
It adds the null terminator back and gives you a pointer you can hand to C. The convention never went away, it just got pushed to the edges of the program, behind an explicit type that makes the cost visible.
The full picture: C strings are bare pointers with an implicit length encoded as a sentinel, a pragmatic decision made under the constraints of its time. Rust stores length explicitly, keeps metadata separate from data, and uses a DST to make slices work uniformly whether the bytes are on the heap, the stack, or baked into the rodata segment. &str exists because str can't. And Deref is the mechanism that bridges the owned heap type with the borrowed slice type, skipping the struct and handing you a fat pointer straight to the bytes.