System calls in depth
If you are not reading this on a carved stone, every character you see on this screen arrived through a system call. Every keystroke you typed triggered one. They run invisibly, underneath everything.
When learning some language, one of the first things you have contact with is how to print stuff on the terminal, perhaps a "Hello World". Let's take C as an example, to print this classic opener we can make use of a procedure called printf(), but underneath that one line, the CPU is switching privilege levels, your register state is being frozen, and the kernel is running on an entirely separate stack, all before the printf returns. By the end, I hope the kernel will feel a little less like a black box.
From binary to process
One of the most important abstractions the OS gives you is a process. When you create a binary, it is just a file stuffed with instructions (and maybe some static data) sitting on the disk. It is the operating system that gives you a running program. That running program is what we call a process.
When you run a program, a lot happens before your first line of code executes. The OS creates an entry in the process list, allocates memory for the program, loads program from disk to memory, set up the stack with argc and argv, clears the registers, and finally hands control to your entry point, main(). From there, the CPU fetches your instructions directly from memory and executes them one by one.
Pretty simple, right? But if your code runs directly on the CPU with no middleman, what stops it from accessing the disk, reading another process's memory, or turning on your camera? You need to ensure all this security while still maintaining efficiency. Sounds like a hell of a problem.
User mode and kernel mode
Thankfully, the CPU itself has a built-in solution. It does not treat all code equally. It runs in two distinct modes, each with a different level of privilege. This mode is not an OS policy, it is hardwired into the processor itself.
The CPU tracks the current mode with a two-bit value called the privilege level. Kernel mode means full access to hardware, memory, and every instruction the CPU can execute. User mode means restricted. If you tried to issue an I/O request while running in user mode, the processor would raise an exception and the OS would likely kill your process.
Your operating system runs in kernel mode. Every program you write runs in user mode.
But every real program needs to do some sort of I/O at some point: read a file, write to the terminal, open a socket. If user mode code cannot do any of that directly, how does it get anything done?
Traps and system calls
Again, the CPU comes to our rescue. It gives us a controlled way to cross that boundary through a mechanism called a trap. A trap is how the CPU transfers control from user mode to the kernel: it stops what it was doing, switches to kernel mode, and jumps to a kernel handler. This happens both when something goes wrong, like a divide by zero or an illegal memory access, and when your program deliberately asks the kernel for help.
But for any of this to work, the kernel has to tell the CPU where to jump when a trap fires. It does this during boot, in a function called trap_init() (the following code is directly from the Linux codebase, at linux/arch/x86/kernel/traps.c):
void __init trap_init(void)
{
/* Init cpu_entry_area before IST entries are set up */
setup_cpu_entry_areas();
/* Init GHCB memory pages when running as an SEV-ES guest */
sev_es_init_vc_handling();
/* Initialize TSS before setting up traps so ISTs work */
cpu_init_exception_handling(true);
/* Setup traps as cpu_init() might #GP */
if (!cpu_feature_enabled(X86_FEATURE_FRED))
idt_setup_traps();
cpu_init();
}Before explaining what matters in this code, let's state something first: beyond the general purpose registers like rax and rdi, the CPU has a set of special registers that hold its own internal configuration state. These are definitely kernel mode only, your program can never read or write them directly. Some of them are relevant to how traps work, and the kernel writes to them during boot so the CPU knows what to do the moment a trap fires.
"How does the CPU know where to jump when an exception like a divide by zero happens?" Good question indeed. The answer is a table the kernel builds during boot called the IDT, Interrupt Descriptor Table. Each entry maps an exception type to a handler address. Divide by zero gets one handler, page fault gets another, illegal instruction gets another. The kernel fills this table with idt_setup_traps() and writes its address into a special CPU register. On newer Intel CPUs that support a feature called FRED, this whole mechanism is replaced with a cleaner design, but that is not our subject today.
Those are the unwanted cases, the errors your program did not ask for. Returning to our question, how can a user mode program do any sort of I/O? Remember that a trap switches the CPU to kernel mode. The CPU gives us a way to trigger one deliberately. Instead of waiting for something to go wrong, your program can intentionally fire a trap, cross the boundary into kernel mode, and ask the kernel to perform a privileged operation on its behalf: write to a file, read from a socket, open a device. That deliberate request is what we call a system call.
And just like exceptions, the CPU needs to know where to jump when a system call fires. Back to trap_init(), the line that handles this is cpu_init(). It looks like generic initialization but it eventually calls syscall_init() inside arch/x86/kernel/cpu/common.c, which writes the system call entry point address into a special CPU register called MSR_LSTAR. When your program fires a system call, the CPU reads that register and jumps there instantly. No table lookup, just one register read and a jump.
Here is the chain, directly from the kernel source:
cpu_init() calls syscall_init():
// arch/x86/kernel/cpu/common.c
void cpu_init(void)
{
// ...
syscall_init();
// ...
}syscall_init() calls idt_syscall_init():
void syscall_init(void)
{
// ...
if (!cpu_feature_enabled(X86_FEATURE_FRED))
idt_syscall_init();
}And finally, idt_syscall_init() is where it happens. The kernel writes the address of its system call entry point into MSR_LSTAR:
static inline void idt_syscall_init(void)
{
wrmsrq(MSR_LSTAR, (unsigned long)entry_SYSCALL_64);
// ...
}From this point on, every syscall instruction executed anywhere on the system will cause the CPU to read MSR_LSTAR and jump to entry_SYSCALL_64. That is where your program lands when it triggers a system call.
More on system calls
Given this mechanism the CPU hands us, how does a program actually trigger a system call? Remember printf() from the beginning? One might think "but it just writes some text to the terminal, why does that need the kernel?"
Because in Linux, writing to the terminal is just like writing to a file. If you have read my networking post, you already know why: every form of I/O in Unix is represented as a file descriptor, a handle to an open resource that lives inside the kernel. Writing to a file requires privileged access.
Your program cannot just reach into the filesystem and put bytes somewhere. That is what write() is for: a system call that says "take these bytes and write them to this file descriptor."
Don't take my word for it. Let's use a tool called strace, which intercepts and prints every system call a program makes as it runs. Take this simple C program:
#include <stdio.h>
int main() {
printf("hello world\n");
return 0;
}Running it under strace gives us:
$ strace ./main
execve("./main", ["./main"], ...) = 0
mmap(...) = ...
openat(..., "/usr/lib/aarch64-linux-gnu/libc.so.6", ...) = 3
...
write(1, "hello world\n", 12) = 12
exit_group(0) = ?Two things stand out here. First, all those calls before write are not your code at all. That is the dynamic linker loading the C standard library before your main even runs. Second, see that there is no printf in the output? Just write. That is because printf lives in libc and eventually calls write(), which is also a libc wrapper, a thin assembly function dressed up as a nice C API.
To trigger a system call, the CPU provides a dedicated instruction called syscall. When executed, it switches the CPU to kernel mode and jumps to entry_SYSCALL_64. But before firing it, your program has to tell the kernel what it wants and pass the arguments. This is done through registers, following a contract called the x86-64 syscall ABI. rax gets the syscall number, and the arguments follow in rdi, rsi, rdx, r10, r8, and r9 in order. The kernel will read exactly those registers when it takes over.
For write(1, "hello world\n", 12) that looks like this:
mov rax, 1 ; syscall number for write
mov rdi, 1 ; fd = stdout
mov rsi, buf ; pointer to "hello world\n"
mov rdx, 12 ; length
syscall ; switch to kernel mode, jump to entry_SYSCALL_64Each system call has a unique number. write is 1, read is 0, open is 2. That number goes into rax before firing syscall, and the kernel uses it to look up the right handler in a table. You can see the full table directly in the kernel source here, or look up any syscall and its arguments by running:
$ man 2 writeThe 2 refers to section 2 of the manual, which is system calls. Every syscall has a page there.
The kernel maintains a table where each syscall number maps to a handler function. That 1 you put in rax is literally just an index into this:
long x64_sys_call(const struct pt_regs *regs, unsigned int nr)
{
switch (nr) {
#include <asm/syscalls_64.h>
default: return __x64_sys_ni_syscall(regs);
}
}The #include <asm/syscalls_64.h> inside the switch is interesting. At build time the kernel runs a script that reads syscall_64.tbl and generates a header that expands to a case for every single syscall. What looks like one line is actually hundreds of cases: case 0: return __x64_sys_read(regs); case 1: return __x64_sys_write(regs); and so on. So nr == 1 calls write, nr == 0 calls read. Do not worry about pt_regs for now, we will get there.
The point is that the syscall number is nothing magical, it is just an index. The kernel looks it up, calls the right function, and does the work.
What happens when syscall fires
Before diving into the entry point assembly, let me clarify a few things.
Each CPU has one set of registers: rax, rdi, rsi, rbx, and the rest. When your program is running, those registers hold your data: local variables, pointers, return values, things your program is actively using. When syscall fires, the kernel takes over on that same CPU using those same registers. If it just starts using them, your program's state is gone.
In a normal C function call, the x86-64 ABI handles this through a split between caller-saved and callee-saved registers. Caller-saved registers like rax, rcx, rdi can be trashed by any function you call. Callee-saved registers like rbx, rbp, r12 through r15 must be restored before returning. Both sides agree on this contract and everyone is happy.
But a syscall is not a normal function call. The kernel does not follow your ABI. It is completely separate code running at a different privilege level. It cannot promise to restore anything. So the kernel has to save everything before it touches a single register. That is the first thing that happens after syscall fires.
But save them where? The kernel cannot use your user stack. Your stack pointer might be corrupted or pointing at garbage. Even if it is valid, the kernel would be writing sensitive data into memory your program can read and modify. So the kernel has its own stack, one per thread, allocated when the thread is created. It lives in kernel virtual memory, above 0xffff800000000000, a region your process can never touch. It does not appear in /proc/PID/maps. It is completely outside your process memory structure, invisible to your program. It sits empty, waiting for a trap to fire.
Now, for the kernel to switch to that stack the moment entry_SYSCALL_64 runs, it needs to know where it is. That is what the TSS (Task State Segment) is for. It is a structure the kernel maintains per CPU core. Its sp0 field always holds the kernel stack address of whichever thread is currently running on that CPU:
struct x86_hw_tss {
unsigned int reserved1;
u64 sp0; /* kernel stack pointer for the current thread */
u64 sp1;
u64 sp2;
// ...
} __attribute__((packed));Every thread has its own kernel stack, allocated at thread creation and fixed for its lifetime. The stack itself never moves. What changes is sp0. Every time the scheduler picks a new thread to run on a CPU, it updates sp0 and a per-CPU variable called cpu_current_top_of_stack to point at that thread's kernel stack:
/* called on every context switch */
void update_task_stack(struct task_struct *task)
{
load_sp0(task_top_of_stack(task));
}This updates both sp0 in the TSS and a per-CPU variable called cpu_current_top_of_stack, always keeping them in sync. By the time entry_SYSCALL_64 runs, that variable already holds the right kernel stack address for the current thread. So when syscall fires, the kernel already knows exactly which stack to switch to. It was prepared by the last context switch and it is waiting to be used.
Remember cpu_init_exception_handling() from trap_init() earlier? That is where the TSS gets registered with the CPU at boot:
void cpu_init_exception_handling(bool boot_cpu)
{
struct tss_struct *tss = this_cpu_ptr(&cpu_tss_rw);
// ...
set_tss_desc(cpu, &get_cpu_entry_area(cpu)->tss.x86_tss);
load_TR_desc();
// ...
}This is a two step process. set_tss_desc() registers the TSS in the GDT, the global table where the CPU looks up system structures. Think of it as adding the TSS to a directory so the CPU can find it. Then load_TR_desc() executes the ltr instruction, which loads that GDT entry into the Task Register, a dedicated CPU register that holds the currently active TSS. After ltr runs, the CPU no longer needs to search the GDT. It already knows where the TSS is, and the moment a trap fires, it reads sp0 from it instantly.
You do not need to memorize any of this. I certainly do not. The important thing is just to understand that all this preparation means the kernel knows exactly which stack to switch to the moment it needs it. It was all wired up at boot, waiting to be used.
To make this concrete, here is the full chain from boot to the moment your syscall lands on the kernel stack:
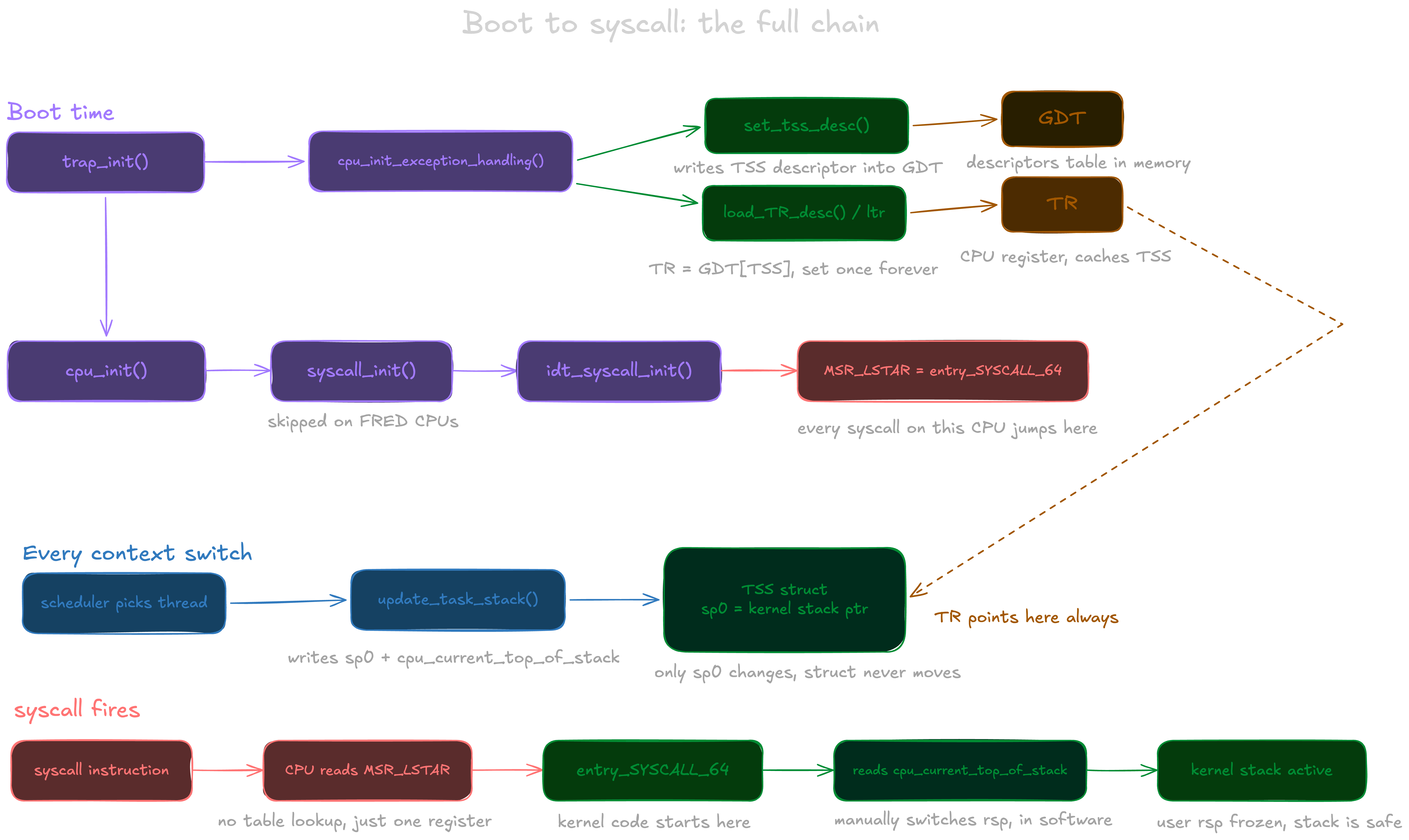
And with all that wired up at boot, your one-line printf can finally make it to the kernel. Remember MSR_LSTAR, the special CPU register the kernel wrote at boot to tell the CPU where to jump when a syscall fires? That address is entry_SYSCALL_64, and we can finally handle the syscall. And if all this complexity just to cross a privilege boundary feels overwhelming, well, now you know why there are not that many operating systems in the world.
Inside the entry_SYSCALL_64
The following is real kernel assembly, don't be scared.
The CPU jumped to entry_SYSCALL_64. Everything we just covered, the TSS wired up at boot, the kernel stack allocated per thread, cpu_current_top_of_stack updated on every context switch, it all comes together in the very first two instructions.
The first thing entry_SYSCALL_64 does is switch to the kernel stack. The kernel does it itself in the very first instructions, reading from cpu_current_top_of_stack, the per-CPU variable that was updated on the last context switch:
movq %rsp, PER_CPU_VAR(cpu_tss_rw + TSS_sp2)
movq PER_CPU_VAR(cpu_current_top_of_stack), %rspYour rsp is stashed into a scratch slot in the TSS and replaced with the kernel stack pointer. The stack is now switched.
Remember when we said the kernel has to save everything before it touches a single register? This is where that actually happens. It builds a pt_regs struct by pushing your registers one by one onto the kernel stack:
pushq $__USER_DS
pushq PER_CPU_VAR(cpu_tss_rw + TSS_sp2) /* your rsp */
pushq %r11 /* rflags */
pushq $__USER_CS
pushq %rcx /* your return address */
pushq %rax /* syscall number */
PUSH_AND_CLEAR_REGSThose pushes map directly onto this struct:
struct pt_regs {
unsigned long r15;
unsigned long r14;
unsigned long r13;
unsigned long r12;
unsigned long bp;
unsigned long bx;
unsigned long r11;
unsigned long r10;
unsigned long r9;
unsigned long r8;
unsigned long ax;
unsigned long cx;
unsigned long dx;
unsigned long si;
unsigned long di;
unsigned long orig_ax; /* syscall number */
unsigned long ip; /* your return address */
unsigned long cs;
unsigned long flags;
unsigned long sp; /* your rsp */
unsigned long ss;
};Every register your program was using is now sitting safely on the kernel stack. PUSH_AND_CLEAR_REGS saves the remaining general purpose registers and zeroes them after. The kernel runs with full privileges, and leaving user controlled values in registers is an attack surface. A clean slate before kernel execution is not optional.
With all of that done, the kernel calls into C:
movq %rsp, %rdi
movslq %eax, %rsi
call do_syscall_64That assembly is literally calling the function below, passing pt_regs as the first argument and the syscall number as the second. Inside it, do_syscall_x64 dispatches to x64_sys_call, the giant switch statement we saw earlier that maps your rax number to the actual handler:
__visible noinstr bool do_syscall_64(struct pt_regs *regs, int nr)
{
nr = syscall_enter_from_user_mode(regs, nr); /* seccomp, audit */
add_random_kstack_offset(); /* security mitigation */
do_syscall_x64(regs, nr);
syscall_exit_to_user_mode(regs); /* check pending signals */
return true; /* use SYSRET */
}
static __always_inline bool do_syscall_x64(struct pt_regs *regs, int nr)
{
unsigned int unr = nr;
if (likely(unr < NR_syscalls)) {
unr = array_index_nospec(unr, NR_syscalls);
regs->ax = x64_sys_call(regs, unr); /* the switch we saw earlier */
return true;
}
return false;
}Whatever the handler returns lands in regs->ax. That is the return value of your syscall, the number of bytes written, the file descriptor, the error code. It will be sitting in rax when your program gets control back.
Once the handler is done, POP_REGS mirrors what PUSH_AND_CLEAR_REGS did, restoring every register from pt_regs back into the CPU. Then the kernel exits with:
sysretqsysretq is the symmetric counterpart to syscall. When syscall fired, the CPU saved your return address into rcx and your flags into r11. sysretq reads them back, restores rip from rcx and rflags from r11, drops the privilege level back to user mode, and jumps to where you left off. One instruction undoes the crossing.
Your program continues as if nothing happened. write returned its byte count, libc handed it back to printf, printf returned, and your main kept running.
To make this concrete, here is the full path from your printf call down to the kernel and back:
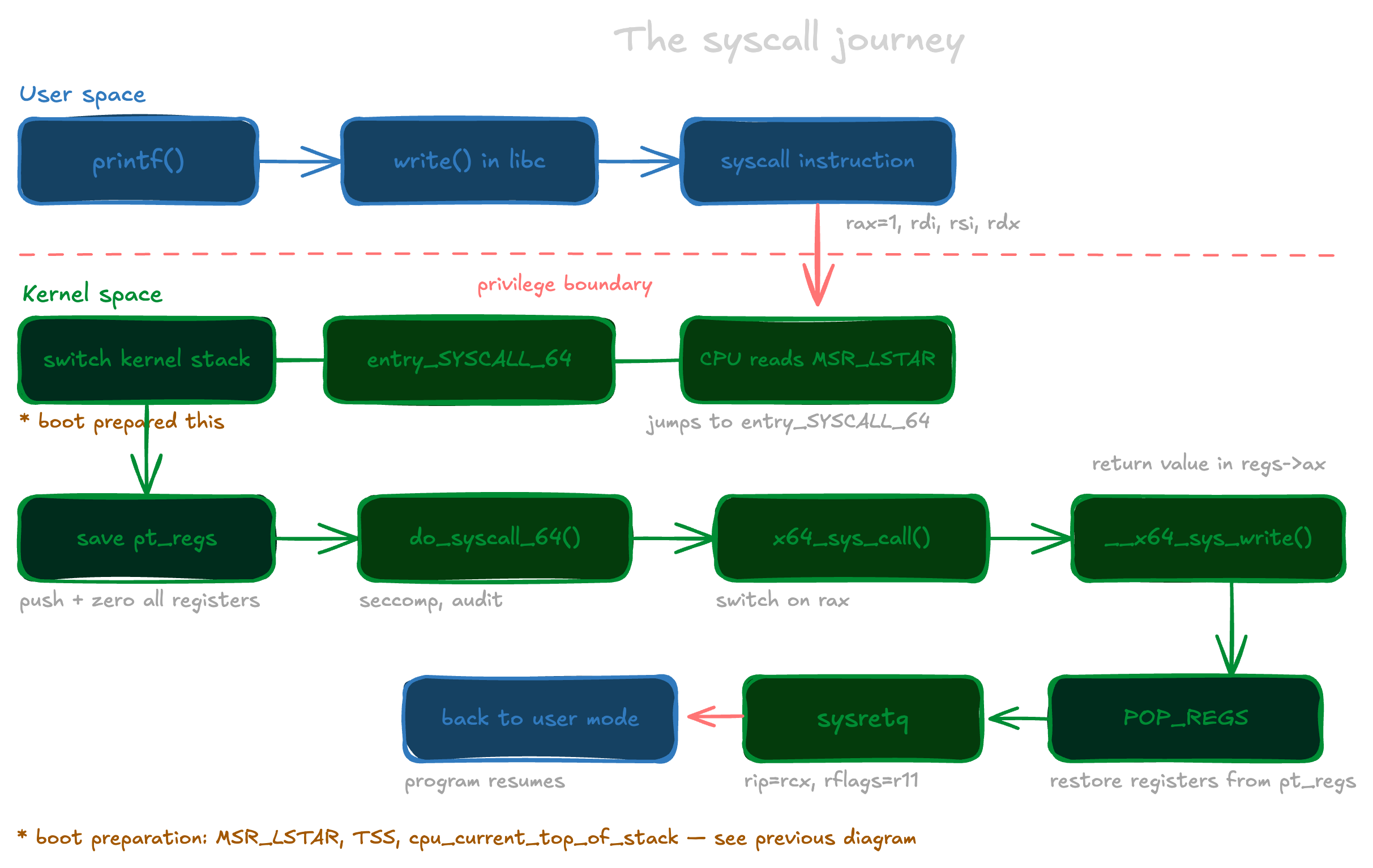
Wrapping up
We started with a single printf("hello world\n") and ended up reading kernel assembly. Along the way we saw how the CPU enforces privilege levels in hardware, how the kernel sets up the IDT and MSR_LSTAR at boot so it always knows where to jump, how every thread has a kernel stack sitting invisible in memory waiting for a trap to fire, and how entry_SYSCALL_64 orchestrates the entire crossing: switching stacks, freezing your registers, dispatching to the right handler, and returning as if nothing happened.
The kernel is not magic. It is just code that runs on the same CPU as yours, with a lot of careful setup done at boot time to make the handoff work. I hope it feels a little less like a black box now.
If you want to go deeper, the next natural steps are signal handling, which happens right before sysretq returns, virtual memory and how the page tables get switched on entry, and the scheduler, which is what keeps cpu_current_top_of_stack always pointing at the right place. Each one of those is its own rabbit hole. But now you have the foundation to read them.